[連載]Clojureで作るAPIの9記事目です。
前回の記事はこちらです。
現在開発しているプロジェクトにはテスト対象自体がまださほどありませんが、先にテストを書ける環境を整えておくことは今後の開発の健全性のために重要です。 そこでこの記事では、テストを実行できる環境を整えていきます。
最初のテスト
テスティングライブラリには公式のclojure.testを使っていきます。
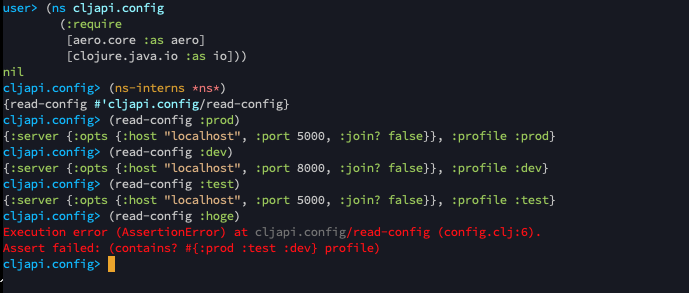
かんたんに設定を読み込む関数のテストを書いてみます。
;; ./test/cljapi/config_test.clj (ns cljapi.config-test (:require [cljapi.config :as sut] [clojure.test :refer [deftest testing is]])) (deftest read-config-test (testing "usable profiles" (is (map? (sut/read-config :dev))) (is (map? (sut/read-config :test))) (is (map? (sut/read-config :prod))) (is (thrown? AssertionError (sut/read-config :hoge)))) (testing "profile included" (is (= :dev (:profile (sut/read-config :dev)))) (is (= :test (:profile (sut/read-config :test)))) (is (= :prod (:profile (sut/read-config :prod))))))
deftest で1つのテストを定義します。一般的にはテストしたい関数名に -test をつけた名前をつけます。
is がclojure.testで中心となるアサーションを行うマクロです。
testing はドキュメンテーションのためのもので、エラー時にどこでエラーが起こっているのかを把握するために書いておくと便利です。
テストはどの開発環境でもエディタ上から実行できます。 テストを書くときはショートカットを使って実行しながらテストを書いていけるようにすべきです。 以下に各エディタごとにテストの実行方法へのリンクを用意しました。参照して実行してみてください。
開発環境自体のセットアップ方法は以下のまとめ等から開発環境の構築方法を参照してください。
テストランナー
ローカル環境はもちろんCI上でも全てのテストをまとめて実行できる環境を作ります。 そのためのテストランナーとしてkaochaを使います。
deps.edn に :test aliasを追加します。
;; ./deps.edn {:paths ["src" "resources"] :deps {org.clojure/clojure {:mvn/version "1.11.1"} info.sunng/ring-jetty9-adapter {:mvn/version "0.17.6" :exclusions [org.slf4j/slf4j-api]} org.clojure/tools.logging {:mvn/version "1.2.4"} spootnik/unilog {:mvn/version "0.7.30"} com.stuartsierra/component {:mvn/version "1.1.0"} aero/aero {:mvn/version "1.1.6"}} :aliases {:dev {:extra-paths ["dev"]} ;; 追加 :test {:extra-deps {lambdaisland/kaocha {:mvn/version "1.68.1059"}} :main-opts ["-m" "kaocha.runner"]} :build {:deps {io.github.clojure/tools.build {:git/tag "v0.8.2" :git/sha "ba1a2bf"}} :ns-default build}}}
次にkaocha公式のおすすめに従って、テストを実行するスクリプトを追加します。
$ mkdir -p bin $ echo '#!/usr/bin/env sh' > bin/kaocha $ echo 'clojure -M:test "$@"' >> bin/kaocha $ chmod +x bin/kaocha
最後にkaochaの設定を追加します。
tests.edn に設定を記述します。
最初は公式ドキュメントのサンプルをそのまま利用します。
;; ./tests.edn #kaocha/v1 {:tests [{;; Every suite must have an :id :id :unit ;; Directories containing files under test. This is used to ;; watch for changes, and when doing code coverage analysis ;; through Cloverage. These directories are *not* automatically ;; added to the classpath. :source-paths ["src"] ;; Directories containing tests. These will automatically be ;; added to the classpath when running this suite. :test-paths ["test"] ;; Regex strings to determine whether a namespace contains ;; tests. (use strings, not actual regexes, due to a limitation of Aero) :ns-patterns ["-test$"]}] :plugins [:kaocha.plugin/print-invocations :kaocha.plugin/profiling] ;; Colorize output (use ANSI escape sequences). :color? true ;; Watch the file system for changes and re-run. You can change this here to be ;; on by default, then disable it when necessary with `--no-watch`. :watch? false ;; Specifiy the reporter function that generates output. Must be a namespaced ;; symbol, or a vector of symbols. The symbols must refer to vars, which Kaocha ;; will make sure are loaded. When providing a vector of symbols, or pointing ;; at a var containing a vector, then kaocha will call all referenced functions ;; for reporting. :reporter kaocha.report/documentation ;; Enable/disable output capturing. :capture-output? true ;; Plugin specific configuration. Show the 10 slowest tests of each type, rather ;; than only 3. :kaocha.plugin.profiling/count 10}
ここまでできたら実際に実行してみます。
$ bin/kaocha --- unit (clojure.test) --------------------------- cljapi.config-tets read-config-test usable profiles profile included 1 tests, 7 assertions, 0 failures. Top 1 slowest kaocha.type/clojure.test (0.02938 seconds, 98.0% of total time) unit 0.02938 seconds average (0.02938 seconds / 1 tests) Top 1 slowest kaocha.type/ns (0.02196 seconds, 73.3% of total time) cljapi.config-test 0.02196 seconds average (0.02196 seconds / 1 tests) Top 1 slowest kaocha.type/var (0.02085 seconds, 69.6% of total time) cljapi.config-test/read-config-test 0.02085 seconds cljapi/config_test.clj:6
Makefileに追加
最後に繰り返し実行できるようにMakefileに追加します。 今後CI上で実行することを考慮して1つでもテストが失敗したらその時点でテストを終了するようにオプションをつけておきます。
.PHONY: format
format:
cljstyle check
.PHONY: lint
lint:
clj-kondo --lint src
.PHONY: static-check
static-check: format lint
.PHONY: clean
clean:
rm -fr target/
# 追加
.PHONY: test
test:
bin/kaocha --fail-fast
.PHONY: build
build: clean
clojure -T:build uber
make test を実行して確認しておいてください。
おわりに
ここまでで1つ単体テストを書き、それをテストランナーを使ってテストを実行できることが確認できました。
コードはGitHubのリポジトリに上げてあります。 09_テストできるようにするというタグからご覧ください。
次はWebサーバーにRouterを追加し、複数のパスに対して異なるレスポンスを返すことができるようにしていきます。
トヨクモでは一緒に働いてくれる技術が好きなエンジニアを募集しております。