こんにちは、開発本部の松尾です。
Clojureは標準ライブラリに使いやすい道具が充実していて、可読性の高い抽象的なコードが書きやすく、Javaとの相互運用のお陰で使える資産も多いため実用的で、良い言語だと思っています。
しかし、おこがましくも1点だけ改善出来るところがあると思っています。それは、「静的型解析が出来ない(弱い)」という点です。
Pythonの型ヒント、Ruby3の静的型チェッカーの例に見られるように、静的型解析によるメリットは、パフォーマンスという観点を抜いても、バグを減らして開発効率を上げる観点から、もはや見過ごすことが出来ないのが時代の潮流だと感じています。特に中規模〜大規模の業務でのコードになってくると、正確さやドキュメント製の観点から重要度が増してくるかと思います。
ということで、静的型解析を出来るようにしていきたいと思いますが、なぜやる必要があるのか。既に他の手段は無いかについて次の項でお話します。
本題を見たい方は読み飛ばしてください。
- なぜやる必要があるのか、代替手段の認識と反省
- 読み進める前に
- 1. Clojureのパーサーを作る。
- 2. ASTを解析しやすいデータ構造に変換する
- 3. データを用いて型を解析していく
- エラーを標準出力する
- エディタで表示する
- 最後に
なぜやる必要があるのか、代替手段の認識と反省
私が認識している中で、Clojureに型という概念を導入する方法は4つあります。
1. メタデータのタグ
^string, ^bytes などのように、シンボルの前につけているやつです。
しかし、Javaとの相互運用の際に最適化に使われるという目的が大きく、バグをへらす為の静的解析に使うにはあまりにも表現力が低いです。例えば、ある形を持ったマップの配列、といったClojureのオブジェクトの型を表現することが出来ません。
2. schema.core
これはトヨクモでも採用しているライブラリです。プリミティブな型やマップの型はもちろん、それらの配列や、Javaの型も扱うことが出来るので表現力は十分です。解析しきれない時は Anyを指定するか、単純に型を付けないかを選べば良く、書いた分だけ見返りが得られて、使っていない部分の開発を妨げることもありません。とても現実的だと思います。しかし、型があっているかどうかは実行時にしか分かりません。主に関数の入力と出力の際に検証をしているので、出せるエラーメッセージには限界があります。また、コードにおける原因と結果が遠いときは問題箇所を見つけづらいという問題意識があります。 また、全てのコードパスを確認するためには、多くのテストを書く必要があります。
3. core.typed Clojureのコードを静的解析することが出来ます。
しかし、以下のリンク先では、CircleCIが実際に導入してから2年後、実用を通して分かった問題点が挙げられています。これは重要参考文献だと思います。 circleci.com
簡単にまとめると以下の通りです。
- 解析が遅い
- 型を解析しきれないことがあり、その際に型チェックを無視するか、複雑な型アノテーションをつけるかを選ばなくてはならない
- サードパーティーコードには型がない。
後発のtypedclojureも出ていますが、開発が非常に盛んというわけではなく、基本的な方針は変わっていないようです。 また、より広く使われているschema.coreを採用している企業にとって、移行コストがかなり高くつくことが予想されます。
4. malli + clj-kondo
これは今回やろうとしていることに近いかと思います。 スキーマとバリデーションの機能を提供するmalliというライブラリが、clojureのリンタである clj-kondoと連携することによって、実行前にスキーマを静的に解析した結果を知ることが出来るようです。
特に大きな欠点はなさそうですが、強いて言えば、他のスキーマライブラリを使っているプロジェクトにおいては移行コストが高く付きそうです。
結論
ということで、既存でも型を解析するツールチェインは存在していますが、トヨクモでも利用していて、比較的広く使われているschema.coreのスキーマを静的解析する、ということには意義がありそうです。
大まかな方針として、既にあるものから漸進的に解析出来る情報を増やしていけば、既存コードに影響を与えることなく、静的解析で得られる情報を増やしていけるのではないか、という算段です。
サードパーティーコードに型がないという問題点は致し方がないと思いますが、他の例を見てみて、解析に必要な情報が足りないときにエラーを出したり、明示的に無視をするのを要求するのではなく、Any(なんでも許容する)という寛容な方に倒し、間違っている確証が得られる箇所のみをエラーとするベストエフォート方式が良いのではないかと思いました。
とはいえ、型が分からないものをそのままにしておくと、Anyが伝播していって全体的に型付けが弱くなってしまったり、Anyの場合にバグを検出することが出来ないという問題があります。 この問題に関しては、型アノテーションで補足をすることで解決出来るかと思います。静的解析が出来ない場合はschema.coreの実行時解析が役に立ちそうです。
速度についてですが、例えば、HTTPのパース、JSONのパースを始めとする何度も実行されるコードはやはり高速であればあるほど良く、そうある努力をすべきだと思っています。 コードの解析もそれに含まれるのではないかと思います。
今回は開発言語にRustを用います。 解析の性質上、取りうる型を網羅的に検査する為に、Rustの強い型付けや代数データ型は非常に有用です。また、解析の速度におけるオーバヘッドにならず、特に意識しなくてもそこそこ高速なことを期待しています。
読み進める前に
この記事は、Clojureを静的型付け言語にした際の機能や実装方法の概要を紹介するものですが、あまり実装の詳細を書いていくと理解しづらくなってしまうため、実装の代わりに「どのようなデータ構造を扱っているのか」という側面で解説していきます。 また、実装の詳細が気になる方の為に、合わせて実際のコードのリンクを近くに貼っておきます。
1. Clojureのパーサーを作る。
解析の準備の為に、Clojureのソースコードの文字列から、Clojureの構文を表すデータ構造に変換する必要があります。文字列からそのようなデータ構造に変換する機構のことをパーサーと呼びます。(大雑把な説明)
Rust製Clojureパーサーは無い気がしたので、まずはClojureのパーサーを作ります。 本題ではありませんので実装方法は割愛しますが、例えば、以下のソースコードを次のように変換出来るように実装します。
(s/defn add-one :- s/Str ;; サンプルコード [a :- s/Int] (+ a 1))
List( Symbol {ns: Some("s"), name: "defn"}, Symbol {ns: None, name: "add-one"}, Keyword { ns: None, name: "-"}, Symbol {ns: Some("s"), name: "Str"}, Vector ( Symbol {ns: None, name: "a"}, Keyword {ns: None, name: "-"}, Symbol {ns: "s", name: "Int"} ) List ( Symbol {ns: None, name: "+"}, Symbol {ns: None, name: "a"}, IntegerLiteral(1) ) )
このとき、コードに影響を及ぼさないコメントや空白などの情報は削ぎ落とされています。 このようなデータ構造を、言語処理系の用語で「抽象構文木」と呼びます。
英語で AST(abstract syntax tree)と略すことが多いので、以降はASTという言葉を使います。
詳細を見たい方は以下のファイル内の型を見るとよりイメージが湧くかもしれません。実際は、位置の情報なども含まれています。
2. ASTを解析しやすいデータ構造に変換する
先程パースしたデータはあくまでリストの中にシンボルなどの下位のASTが入っているものに過ぎません。 つまり、関数ということが分かっているのではなく、「ただのリスト」に過ぎないのです。
他のLisp以外の言語は構文の種類がより多く、ASTの時点で意味合いが具体的に決まっていることが多いため、文字列からパースした段階でその情報を得られることが多いですが、Clojure(Lisp)は構文がリスト、ベクタ、リテラルぐらいしかなく、自由度が非常に高いので、ここから更に意味を抽出していきます。
Clojureの内部構造としては、def, defn, if, let などの特殊形式はマクロとして定義されていますが、これを展開して解析しようとするとキリが無いので、ある程度決め打ちでこちらが分かる範囲のデータに持ち込むというわけです。
先程のASTから以下のようなデータを生成します。
Function ( decl: FunctionDecl, name: "add-one", arguments: [ (Binding::Simple("a"), Some(Scalar("Int"))) // Int型 ] return_type: Some(Scalar("Str")), body: [ Call { func_expr: Symbol {ns: None, name: "+"}, args: [ SymbolRef {ns: None, name: "a"] IntegerLiteral(1) ] } ] )
例えば、defnから始まるリストが、Function、それに続くシンボルが名前、その後のベクタが引数、 + から始まるリストが Call、というように、defnマクロが持つ意味に従って再解釈されています。
他にも特殊形式はあると思います。例えば、ifやwhenなどがありますが、これらもそれぞれのマクロが持つ意味に従って解釈していきます。
詳細を見たい方は以下のファイル内の型を見るとよりイメージが湧くかもしれません。
3. データを用いて型を解析していく
さて、ここまで作成してきたデータにより、型を解析するための準備は揃っています。 後は以下のことを出来るようにするだけです
- 関数、変数、スキーマの型解決
- 型シンボルを比較可能な形式に解決
- 型が他の型に代入できるかのロジックの実装
- 関数呼び出し、定義、代入、関数の戻り値などに関して、型が定義されたものに一致するかを検査する
関数、変数、スキーマの型解決について 簡単な実装方法を紹介します。 変数の参照先の解決という問題は、「スコープ」という概念と、あるスコープの中で参照出来る変数というデータを表現することによって解決することが出来ます。
例えば以下のような 関数定義があったとします
(s/defn say-hello [to :- s/Str] (println to)
このとき、[to :- s/Str] の後の (println to) の部分が関数のボディにあたりますが、この中では、to という変数を参照出来るようになっていて、s/Str型を持っているということも分かるはずです。
この情報を defn に対応するデータを読み込んだ際にマップに保存していきます。
スコープはネストされていくものなので、深さによって変数が指す値が変わることがあります。そのため、マップの可変長配列 というデータ型で、関数や変数、スキーマを解決するためのデータを表現することが出来ます。
以下に実際のコードの関数の解析の例を載せておきます。
pub fn analyze_function(errors: Errors, context: Context, func: &Function) { let func_ty = get_func_type(context.clone(), &func.decl); context .borrow_mut() .variable_scopes .last_mut() .unwrap() .insert(func.decl.name.clone(), func_ty); variable_scope!(context, { for (arg_binding, opt_arg_ty) in &func.decl.arguments { match &arg_binding.value { semantic_parser::semantic_ast::Binding::Simple(name) => { let arg_ty = if let Some(arg_ty) = opt_arg_ty { context.borrow().resolve_type(&arg_ty).clone() } else { ResolvedType::Unknown }; context .borrow_mut() .variable_scopes .last_mut() .unwrap() .insert(name.clone(), arg_ty); } semantic_parser::semantic_ast::Binding::Complex { keys, alias } => todo!(), } } for expr in &func.exprs { analyze_expression(errors, context.clone(), expr); } }); }
このような関数を書いていきます。特にClojureは ifもwhenも様々なものが「値」なので、値の解析については再帰的に解析することになります。
その際も let forなど変数を束縛するマクロがあれば、スコープを追加して値を設定していきます。そして、それらの値も解析が終わる際にスコープをpop(削除)します。
この実装により変数などの型が解決出来るので、例えば、関数呼び出しの際に、以下のように型が間違っているかどうかが判定出来るようになります。
(say-helllo ;; s/Strを受け取る関数であることが分かっている 1) ;; リテラルはそのまま s/Intであることが分かるので、これはエラーとなる
実際の実装のリンクも貼っておきます。
エラーを標準出力する
以上で紹介した実装方法によって、型が間違っている箇所をエラーとして蓄積していきます。 あとは集まったエラーを標準出力に出力するだけです。以下のようなイメージです。
for error in errors { println!("{}:{}:{}: {}", file_path, error.location.line, error.location.col, error.message) }
エディタで表示する
標準出力だけでも有用かもしれませんが、普段の開発に組み込むことを考えれば、エディタ上でエラーを表示出来るのが望ましいです。 今回は弊社で広く使われている IntelliJ での方法を紹介します。
まず、IntelliJのプラグインであるFileWatcherを導入します。
設定 > ツール > FileWatchersを開き、リストに設定を追加します。
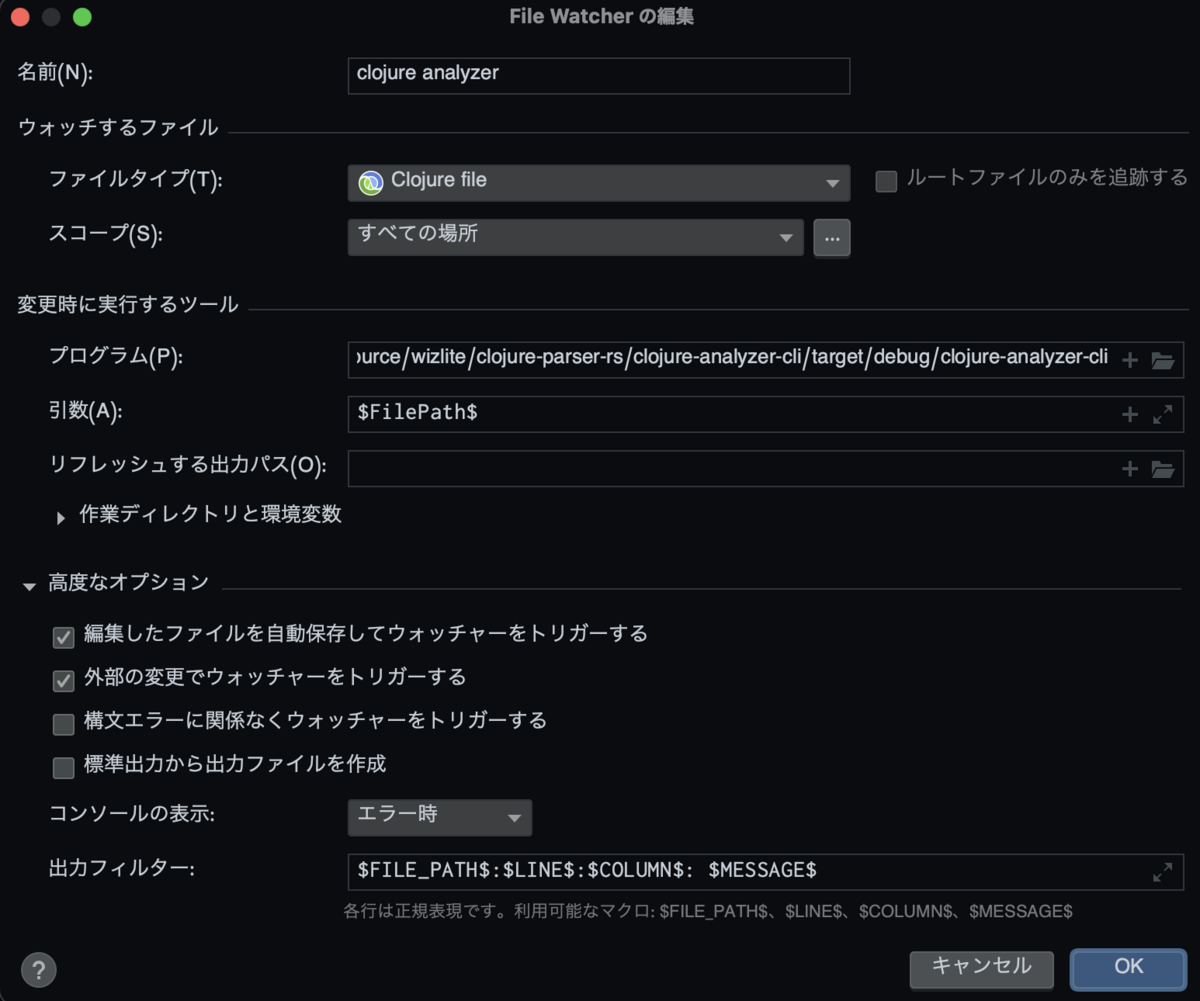
肝はこの部分です。この部分を標準出力の形式に合わせるだけで、保存時に出た標準出力をパースして、該当位置に波線が引かれるようになります。

ホバーすると、$MESSAGE$ の内容のツールチップを表示してくれます。

最後に
今回は、Clojureのパーサーから書いた為に結構な実装量になりましたが、これでClojureの静的解析をするための基礎が出来ました。まだ初歩的なものだしバグも多いかもしれませんが、このプログラムを漸進的に成長させて、実際に業務で使えるところまで持っていきたいという所存でいます。
他にも
- 他のファイルやライブラリの読み込み、namespaceの解決
- 標準ライブラリへの組み込み型付け
- サードパーティーコードへの型付けの提供
などやることが多く考えられます。 もし、Clojureの静的解析に興味を持っていただけた方は、ご意見、感想を頂けると励みになります。 最後まで読んで頂きありがとうございます。
トヨクモでは一緒に働いてくれる技術が好きなエンジニアを募集しております。