北川です。
Symfony アプリを AWS Elastic Beanstalk Multi-Container Docker を用いて構築・運用する事例の紹介です。
弊社が提供するフォームブリッジというサービスは実際にこの記事の内容に基づき作られています。
なおベストプラクティスを模索中だったり、生々しい妥協案も出てくるので暖かい目で読んでいただきますと幸いです。
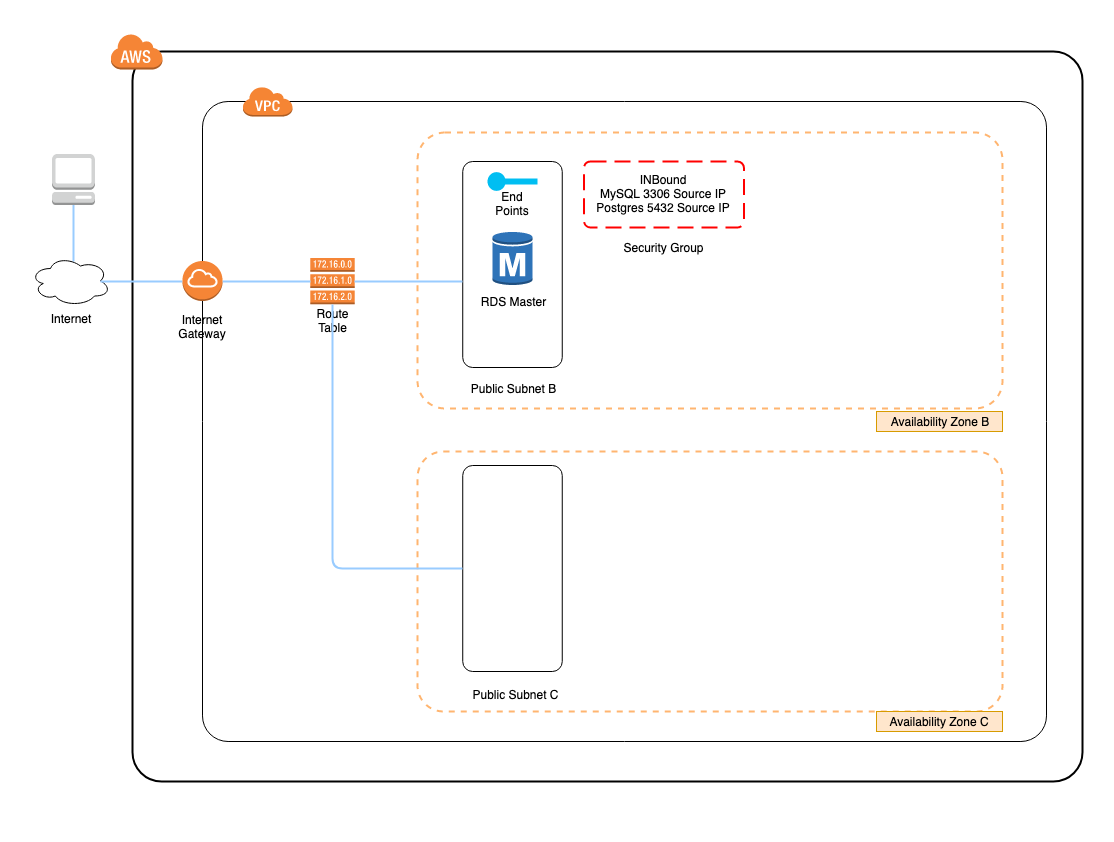
構成
- Nginx
- Symfony, Composer
- Vue, Yarn
フロントエンドとバックエンドがある程度分離されたSPA
Symfonyアプリでの事前準備
EB での運用を快適にするためにはアプリ側にもいくつか要件があります。
環境変数の設定
アプリの振る舞いを変える方法を環境変数のみにしておきます。
Symfony では parameters.yaml を配置して振る舞いを変えますが、parameters.yaml から環境変数を読み込ませる機能がありますのでこれを利用します。Symfony 3系でも使えます。
# parameters.yaml parameters: database_host: '%env(DATABASE_HOST)%' database_port: '%env(int:DATABASE_PORT)%' database_name: '%env(DATABASE_NAME)%' database_user: '%env(DATABASE_USER)%' database_password: '%env(DATABASE_PASSWORD)%'
注意点として、環境変数にセットした値がデフォルトでは string でパースされるのでポート番号など型を指定したい場合は '%env(int:DATABASE_PORT)% のように記述する必要があります。
環境変数は EB の環境プロパティでセットします。
ログを標準出力に出す
必要なログを標準出力に出し CloudWatch にストリーミングするようしておくと ssh で接続してファイルを取得といったことをする必要が無くなります(後述)。 また Docker でコンテナ内のログファイルを永続化するのは面倒です。 このためアプリケーションログはファイルでは無く標準出力に出しておくと便利です。
monolog を使用した例です。
# config.yaml monolog: handlers: main: type: fingers_crossed action_level: error handler: nested nested: type: stream path: "php://stdout" level: debug console: type: console
CI やテストがやかましくなるので test env ではファイルに出力するようにしておくと良いでしょう。
ジョブのAPI化
バッチサーバーなどを EB で運用する場合、Worker環境を使うことになります。 詳細はドキュメントを読めば分かりますが、Woker環境の仕組み上、HTTPリクエストを受けジョブを実行する流れになります。 逆に言えば、Web環境とまったく同じ構成でWorker環境を作ることもできます。FormBridge でも Web と Worker は同じ構成です。
例えば、バッチサーバーで以下の cron を実行している場合、Symfony の Controller にアクションを追加し処理を移行すれば良いです。スケジューリングは cron.yaml という仕組みが用意されています(後述)。
0 9 * * * php /var/www/html/app/bin/console app:hoge
非同期ジョブなどはWorker環境では以下のように処理します。
- SQS にメッセージを送信
- aws-sqsd がメッセージを取得し指定のpathにHTTPリクエスト
- ジョブを実行
この場合、SQS にメッセージを送信する部分とジョブのAPI化の2箇所を対応する必要があります。
Docker のビルド
ECR
イメージのリポジトリには ECR を利用しています。タグ運用をする場合はイメージタグの変更可能性を変更不可にしておくと事故が減ります。
PHP Dockerfile
FROM composer:version as composer WORKDIR /app COPY . /app/ RUN composer install --no-dev FROM php:7.2-fpm WORKDIR /app RUN apt-get update && apt-get install -y ... RUN docker-php-ext-install ... RUN pecl install ... ADD ./path/to/ini/*.ini $PHP_INI_DIR/conf.d/ COPY . /app/ COPY --from=composer /app/vendor /app/vendor RUN cp app/config/parameters_env.yaml app/config/parameters.yaml RUN chown -R www-data:www-data /app
ところどころぼかしていますが、これが Symfony アプリのイメージビルドに使用している Dockerfile です。ソースコードを丸ごとコピーしているように見えますが .dockerignore で不要なディレクトリをコピーしないようにしています。parameters_env.yaml は、先ほどの環境変数を読み込むようにした parameters.yaml のことです。最後にデフォルトの PHP-FPM 実行ユーザーの www-data にパーミッションを変更しています。
Nginx Dockerfile
FROM node:version as node WORKDIR /app ADD ./package.json /app/ ADD ./yarn.lock /app/ RUN yarn install RUN yarn build FROM nginx:version ADD ./path/to/nginx.conf /etc/nginx/nginx.conf ADD ./path/to/default.conf /etc/nginx/conf.d/default.conf COPY ./document-root /app/document-root COPY --from=node /app/document-root/dist /app/document-root/dist
ところどころぼかしていますが、これが Nginx での最も単純な Dockerfile です。Nginx には静的コンテンツを管理している document-root と webpack でのビルドの成果物のみを配置します。
ところが、使用しているライブラリによってはこう単純にはいかず、実際には以下のような Dockerfile を使っています。
FROM composer:version as composer WORKDIR /app ADD . /app RUN composer install FROM node:version as node WORKDIR /app ADD . /app/ RUN yarn install COPY --from=composer /app/document-root/js /app/document-root/js RUN yarn build FROM nginx:version ADD ./path/to/nginx.conf /etc/nginx/nginx.conf ADD ./path/to/default.conf /etc/nginx/conf.d/default.conf ADD ./document-root /app/document-root COPY --from=composer /app/vendor /app/vendor COPY --from=composer /app/document-root/bundles /app/document-root/bundles COPY --from=node /app/document-root/dist /app/document-root/dist
node のマルチステージビルドでは、 composer でインストールしたライブラリに同梱された js/css が document-root/js に落ち、その中から必要な js/css を yarn build の成果物に含めるようにしています。どんな状況だよという感じですね。
下の方では composer でインストールしたライブラリに同梱された js/css が document-root/bundles に落ちてくるパターンに対応しています。document-root/bundles からさらにシンボリックリンクが vendor 以下に貼られる場合もあるので vendor もイメージに含めています。vendor は js/css のみを目当てに配置しているということです。つらい。
Elastic Beanstalk 設定ファイルの管理
ディレクトリ構成
EB 管理用リポジトリは下記のようなディレクトリ構成を取ります。
.gitignore
eb
├── production
│ ├── worker
│ │ ├── .ebextensions
│ │ │ ├── ...
│ │ │ └── cache_clear.config
│ │ ├── .elasticbeanstalk
│ │ │ └── config.yaml
│ │ ├── Dockerrun.aws.json
│ │ └── cron.yaml
│ └── web
│ ├── .ebextensions
│ │ ├── cache_clear.config
│ │ ├── ...
│ │ └── migrate_db.config
│ ├── .elasticbeanstalk
│ │ └── config.yaml
│ └── Dockerrun.aws.json
└── staging
├── worker
│ ├── .ebextensions
│ │ ├── ...
│ │ └── cache_clear.config
│ ├── .elasticbeanstalk
│ │ └── config.yaml
│ ├── Dockerrun.aws.json
│ └── cron.yaml
└── web
├── .ebextensions
│ ├── cache_clear.config
│ ├── ...
│ └── migrate_db.config
├── .elasticbeanstalk
│ └── config.yaml
└── Dockerrun.aws.json
production と staging の2種類のEBアプリケーションがあり、それぞれのEBアプリケーションはworker環境とweb環境を持ちます。 各環境には .ebextensions/, .elasticbeanstalk/, Dockerrun.aws.json が配置されています。
config.yaml
デプロイの利便性のため .elasticbeanstalk/config.yaml をソース管理に含めています。EB CLI コマンド の eb init を実行した場合、デフォルトではソース管理から外されますがあえてソース管理しています。
# .gitignore # Elastic Beanstalk Files eb/**/.elasticbeanstalk/* !eb/**/.elasticbeanstalk/config.yaml #追加
config.yaml にはEBアプリケーション名および環境名を記述します。
# config.yaml branch-defaults: default: environment: web ... global: application_name: formbridge-production ...
各環境ディレクトリに対して eb deploy を実行することでデプロイを行います。
弊社では完全な自動化はしていませんが、さらに .ebextensions 以下に config を追加したりJSONドキュメントを活用することで eb deploy だけでなく eb init や eb create による自動化も達成できるはずです。
Dockerrun.aws.json
各環境毎の Dockerrun.aws.json では ECR リポジトリとイメージタグの指定やログの設定を行なっています。
# Dockerrun.aws.json { "AWSEBDockerrunVersion": 2, "containerDefinitions": [ { "name": "php", "essential": true, "memory": 1024, "image": "xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/php-repository-name:tag", "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "/aws/elasticbeanstalk/containers/php" } } }, { "name": "nginx", "essential": true, "memory": 256, "image": "xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-repository-name:tag", "links": [ "php" ], "portMappings": [ { "containerPort": 80, "hostPort": 80 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "/aws/elasticbeanstalk/containers/nginx" } } } ] }
Dockerrun.aws.json のコンテナ定義セクションとボリュームセクションは、Amazon ECS タスク定義ファイルの対応するセクションと同じ形式を使用できますので、logConfiguration を設定し CloudWatch へログをストリーミングしています。awslogs-group に対応するロググループを CloudWatch 上で手で作成する必要があります。
cron ジョブ
Worker環境に cron.yaml を配置すると cron のように定期的なタスクを実行することができます。
# cron.yaml version: 1 cron: - name: "hoge" url: "/hoge" schedule: "0 0 * * *"
注意点としては、スケジューリングをUTCで指定する必要があることと、FIFOキューとの併用ができないことです(2019.8 時点)。実際に動かしてみると cron.yaml を元にキューにメッセージを詰める aws-sqsd がエラーを出すので単に対応していないようです。このためFIFOキューを使うWorker環境が欲しい場合、cronジョブを捌く環境とは別の環境を用意すると良さそうです。
.ebextensions
Symfony アプリの運用では cach_clear.config と migrate_db.config があると便利なので紹介します。それぞれDockerコンテナ起動後に実行されるコマンドです。
上記のディレクトリ構成ではこれらのファイルが重複し冗長な構成となっていますが、別にいいんじゃないかなという気持ちです。
# cache_clear.config
files:
"/opt/elasticbeanstalk/hooks/appdeploy/post/99_cache_clear.sh":
mode: "000755"
owner: root
group: root
content: |
#!/usr/bin/env bash
docker exec `docker ps --no-trunc | grep container-name | awk '{print $1}'` php bin/console cache:clear -e prod
docker exec `docker ps --no-trunc | grep container-name | awk '{print $1}'` chown -R www-data:www-data /app/var/cache
Symfony は Cache まわりがよく問題となるので、どこかのタイミングで php bin/console cache:clear を実行し Cache を削除しておくと安心です。この例では root ユーザーで実行しているので PHP-FPM の実行ユーザー www-data にパーミッションを戻しています。
# migrate_db.config
files:
"/opt/elasticbeanstalk/hooks/appdeploy/post/10_post_migrate.sh":
mode: "000755"
owner: root
group: root
content: |
#!/usr/bin/env bash
if [ -f /tmp/leader_only ]
then
rm /tmp/leader_only
docker exec `docker ps --no-trunc | grep container-name | awk '{print $1}'` php bin/console doctrine:database:create --if-not-exists
docker exec `docker ps --no-trunc | grep container-name | awk '{print $1}'` php bin/console doctrine:migrations:migrate --allow-no-migration
fi
container_commands:
01_migrate:
command: "touch /tmp/leader_only"
leader_only: true
migrate_db.config のポイントは冗長化されていても1回だけ実行するためにリーダーインスタンスのみで実行していることです。
デプロイ
ローリングデプロイ
EB コンソールで次のような設定をしておくとデプロイ時にコンテナ起動中の状態で公開されてしまい 502 Bad GateWay といった事態を無くすことができます。

手順
最後にこれまでのまとめとしてデプロイの手順を紹介します。例として eb/production/web の環境にデプロイします。
# イメージタグを更新する vi eb/production/web/Dockerrun.aws.json # 本番用イメージのビルド docker build -t nginx-image /path/to/nginx/Dockerfile docker build -t php-image /path/to/php/Dockerfile # ECRにログイン aws ecr get-login --no-include-email --region ap-northeast-1 # イメージを ECR にプッシュ docker tag nginx-image:latest xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-repository:tag docker tag php-image:latest xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/php-repository:tag docker push xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-repository:tag docker push xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/php-repository:tag # eb へデプロイ cd eb/production/web eb deploy
あとはこれと似たようなものをそれぞれの環境についても記述し、お好みのツールとビルド環境で自動化すればおしまいです。
トヨクモでは一緒に働いてくれるエンジニアを募集しております。